data structures & algorithms¶
In programing, data structures play such a pivotal role in everything we implement from data to software that you just can't avoid not talking about it or learning about it as much as you can! Obviously, so relevant that students are often required to digest as a full semester college course idn CS. Let's get to this now!
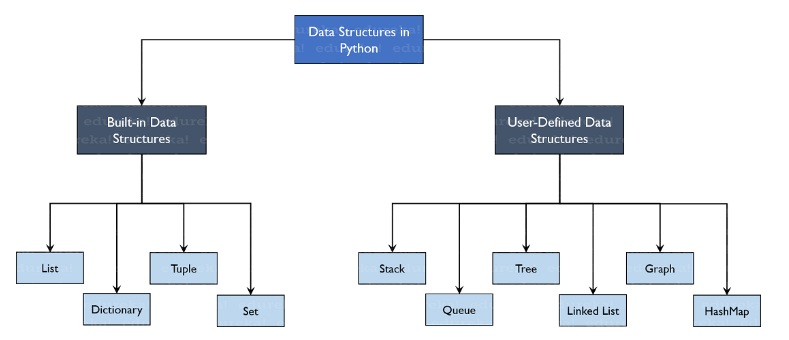
data structures and sequence types¶
A quick intro on a few really important data structures that are being used across the board. I won't dive into these as there are lots of great docs and tutorials everywhere.
- lists (mutable in "[]") - super versatile and interoperable for various data types you're trying to manipulate/parse.
- dictionaries (aka hashmaps depending on which language you're using) - be wary of hash collision, otherwise key:value pairs are awesome ways to optimize data retrieval.
- sets (mutable in "()") - great for identifying unique elements via data intersection, union, and any interoperations between datasets such as merging 2 joined lists without dups.
- tuples (immutable in "()") - useful when you have a dataset that shouldn't be changed, or use it like a dictionary except without a dict.key() format as a lookup value. It's also more memory efficient than a list.
- str (immutable), unicode points to store textual data
- range (immutable), sequential numbers of generated executaion. Typically use to identify the total length (len) of an array to iterate on.
common techniques & manipulations¶
"""
Some common data structure manipulations using various techniques to parse,
convert, transform, or extract data structure from one to another.
"""
l1 = [1, 2, 4, 8, 8, 9]
l2 = [6, 3, 0, 6, 10]
l3 = ["x", 3, "y", 7, "z", 8]
nums = [1, 3, 9, 6, 9, 1, 4]
arr1 = [2, 3, 5, 5, 11, 11, 11, 13]
arr = [1, 2, 2, 3, 4, 4, 4, 5, 5]
m1 = [[2, 3], [4, 5], [7, 6]]
m2 = [[4, 9], [4, 2], [11, 10]]
d1 = {1: "a", 2: "b", 3: "c", 4: "d"}
input_data = ("Hello", "TutorialsPoint", "Website")
def create_unique_list(l1, l2):
"""Create a new list by merging two lists with unique elements
using list comprehension and set().
return -> [0, 1, 2, 3, 4, 6, 8, 9, 10]
"""
newlist = l1 + [i for i in l2 if i not in l1]
return list(set(newlist))
def convert_list_to_tuple(l1):
"""Convert a list to a tuple. Use range() to pass in the args if int object
isn't iterable. You can also verify if your object is iterable
by doing a quick print(dir(l1)) to verify methods __iter__ exists or not.
return -> (1, 2, 4, 8, 8, 9)
"""
return tuple(i for i in l1)
def convert_list_to_dict(l2, l3):
"""Convert a new list into a dictionary using dict comprehension.
return -> newdict1 = {'x': 3, 'y': 7, 'z': 8}
return -> newdict2 = {6: 36, 3: 9, 0: 0, 10: 100}
"""
newdict1 = {l3[i]: l3[i + 1] for i in range(0, len(l3), 2)}
newdict2 = {n: n * n for n in l2}
return newdict1, newdict2
def transpose_list_to_dict(l3):
"""Use zip() to transpose two values by creating an iterator of tuples,
then typecast the return value.
return -> {'x': 3, 'y': 7, 'z': 8}
"""
# first, create an iterator
_iter = iter(l3)
# typecast to dict()
res = dict(zip(_iter, _iter))
return res
def transpose_two_lists(l1, l2):
"""This zips two lists togethers.
return -> [(1, 6), (2, 3), (4, 0), (8, 6), (8, 10)]
"""
return list(zip(l1, l2))
def merge_two_lists_using_map(m1, m2):
"""Use functional programming, map() and addition operator to merge
two lists from first to second elements of iterables.
return -> [[2, 3, 4, 9], [4, 5, 4, 2], [7, 6, 11, 10]]
"""
res = list(map(list.__add__, m1, m2))
return res
def generate_iterable_index(l3):
"""Generate indices using enumerate() for both key and values in a dictionary.
return ->
0 x
1 3
2 y
3 7
4 z
5 8
"""
for i, key in enumerate(l3, start=0):
print(i, key)
def generate_index_in_dict(d1):
"""This creates indices by enumerating keys and values in a dictionary.
If excluding dict.items(), the output is <index, value> and not a tuple.
return -> <index, value>
0 1
1 2
2 3
3 4
return -> <index, tuple>
0 (1, 'a')
1 (2, 'b')
2 (3, 'c')
3 (4, 'd')
"""
for i, val in enumerate(d1):
print(i, val)
for i, tup in enumerate(d1.items()):
print(i, tup)
def get_second_largest_element(l1):
"""Get second largest element in an array.
return -> 8
"""
array = sorted(list(set(l1)))
print(f"second largest element in an array is: \n{array[-2]}")
def find_duplicates_in_array_list_comprehension(l1):
"""Use list comprehension to get duplicate.
return -> 8
"""
return list(set([n for n in l1 if l1.count(n) > 1]))
def find_duplicates_pythonically(l1):
"""Use list-dictionary pythonic approach to find dups
return -> 8
"""
new_dict, new_list = {}, []
# look for dups using a dictionary
for n in l1:
if n not in new_dict:
new_dict[n] = 1
else:
new_dict[n] += 1
# then output the dup into a new list
for k, v in new_dict.items():
if v > 1:
new_list.append(k)
return new_list
def find_two_sums(nums, target):
"""_summary_
Args:
nums (_type_): _description_
target (_type_): _description_
Returns:
_type_: _description_
"""
lookup = {}
for i, val in enumerate(nums):
if nums[i] in lookup:
# return index
return [lookup[nums[i]], i]
else:
lookup[target - nums[i]] = i
return None
def delete_duplicates_from_sorted_array(arr: list[int], n) -> int:
"""gesths"""
# checks base case if it's an array
# 1, 0 = True, False
# if not arr: return 0 # False
# checks
if n == 0 or n == 1:
return n
temp = list(range(n))
# checks if current element is not equal to next
# we store them to new list temp
j = 0
for i in range(0, n - 1):
if arr[i] != arr[i + 1]:
temp[j] = arr[i]
j += 1
# store last element, that's not previously stored
temp[j] = arr[i - 1]
j += 1
# modify original arr
for i in range(0, j):
arr[i] = temp[i]
return j
if __name__ == "__main__":
# print(f"new list is: {create_unique_list(l1, l2)}")
# print(f"new tuple is: {convert_list_to_tuple(l1)}")
# print(f"new dict1 and dict2: {convert_list_to_dict(l2, l3)}")
# print(f"transpose list to dict is: {transpose_list_to_dict(l3)}")
# print(f"tranpose two list using zip(): {transpose_two_lists(l1, l2)}")
# print(f"merge two list using map() is: {merge_two_lists_using_map(m1, m2)}")
# print(f"iterable index using enumerate() is: {generate_iterable_index(l3)}")
# print(f"generate index in a dict: {generate_index_in_dict(d1)}")
# print(get_second_largest_element(l1))
# print(find_duplicates_in_array(l1))
# print(find_duplicates_pythonically(l1))
# print(find_two_sums(nums, 15))
# print(delete_duplicates_from_sorted_array(arr, len(arr)))
n = len(arr)
n = delete_duplicates_from_sorted_array(arr, n)
# Print updated array
for i in range(n):
# print(f"{arr[i]}, end=" "}")
print("%d" % (arr[i]), end=" ")
time and space complexity snapshot¶
Algorithms are measured by time and space complexity. This denoted by Big O (Lambda) notation. Big O expresses runtime complexity, and how quickly algorithms grow relative and/or proportional to input size, n. It also represents the # of steps it takes to find a solution.
Time complexity is measured based on the function of the input size, which can affect the time it'll take for the algorithm to execute efficiently.
Space complexity is measured by the memory the algorithm needs to run.
- O(1) - constant. Input size is irrelevant. - Examples: - Finding an element in a hash table, where the value is not size dependent. - Finding a min value, where an array takes a constant time, only if element is sorted. - Tips: - if an array is unsorted, it's not constant time, as it needs to linearly scan over each element to find the min value.
- O(n) - linear. This is semi-efficient, depending on how your algorithm is designed. It can be efficient if it's a sorted array for instance.
- O(logn) - logarithmic. The most efficient. - Example: Binary search tree is the perfect example that uses this time/space complexity.
- O(n^2) - quadratic. The least effficient. - Examples: - Finding duplicate values in a list, where each item has to be checked twice.
- O(2^n) - exponential. This is very inefficient. Runtime increases with size n as input.
popular data structure algorithms¶
Pretty much many coding interviews revolves around DSA on Linkedlist (doubly and singly), binary search tree (sorted and unsorted BST), stacks (LIFO), queues (FIFO with enqueues and dequeues), sorting algorithm, searching algorithm, merging algorithm, depth-first search algorithm (DFS), and bread-first search algorithm (BFS).
I'm going to dive deeper into each of one of these DSA's. Some common algorithm implementations and example use cases, as well as ones I was asked during interviews at Google, and Meta.
linked list (doubly vs singly)¶
In pretty much every interview questions, it involves some kind of linked lists questions. Single linked list, doubly linkedlist, hash table using linked lists if you have a hash collision, that is. And then there are questions about arrays vs linked lists, which is better data structure to solve a particular algorithm? What are the pros and cons between them? What are their time and space complexity representations?
In simple terms, linked lists are essentially blocks (nodes) that are chained, or connected into a sequential structure forming a list. At the beginning of the list, is the head node, connected by a pointer to the next node, and this gets repeated until the node reaches a null, then we know its at its tail end and stops.
We know that linked lists is a very popular data structure as it's highly applicable in many real world examples. Let me provide some context here:
- New York subway train stations (doubly linked lists)
- Greyhound Amtrak (doubly linked lists)
- One way flights with multiple connections (singly linked lists)
- Cycling using the a single path trail, stopping in between peaks through the Switzerland's Alps, until you reached Eiger. (singly linked lists)
time-space complexity¶
Linkedlist has a time-space complexity of O(n). Every pointer has to loop through each node from the linkedlist' head node until it reaches to the tail node to get to a null value.
basic implementation¶
"""
You'll need to build a linked list Node() object first to create and track each
node that gets traversed. This helps us build the linked list and modify the list as we go.
"""
class Node:
"""Node object with a constructor allows for creating a new Node dynamically from each of the LinkedList object's
methods."""
def __init__(self, value) -> None:
"""Create a new Node."""
self.value = value # to be assigned to the node
self.next = None
class LinkedList:
def __init__(self, value) -> None:
new_node = Node(value)
self.head = new_node
self.tail = new_node
self.length = 1 # keep track of length of the list
def append(self):
"""Create a new Node and add Node to end"""
new_node = Node(value)
if self.length == 0:
self.head = new_node
self.tail = new_node
else:
self.tail.next = new_node
self.tail = new_node
self.length += 1
def prepend(self):
"""Create a new Node and add Node to beginning"""
new_node = Node(value)
if self.length == 0:
self.head = new_node
self.tail = new_node
else:
self.head.next = new_node
self.head = new_node
self.length += 1
def insert(self):
"""Create a new Node and insert Node based on index"""
new_node = Node(value)
if self.length == 0:
self.head = new_node
self.tail = new_node
else:
self.tail.next
my_linked_list = LinkedList(1)
my_linked_list.append(2)
common leetcode algorithms¶
# remove an element in a linked list using linked list methods
def remove_element(nums, val):
# Initialize the index variable to 0
i = 0
# Iterate through the array using a while loop
while i < len(nums):
# Check if the current element is equal to the given value
if nums[i] == val:
# If equal, remove the element in-place using pop()
nums.pop(i)
else:
# If not equal, increment the index to move to the next element
i += 1
# Return the new length of the modified array
return len(nums)
sorted BST¶
Binary search is a very popular tree data structure particularly when you have a ginormous dataset, and you want to find a element that matches a specific target (e.g. the min or max value in an array), and assuming is already sorted for this to work because it helps eliminate 1/2 of the search possibilities for comparison between left and right side of the array.
The array can be split up into two halves, in repeated 1/2 intervals between left and right, where the bisection is at midpoint to find the target.
The # of comparisons will be smaller as you iterate through the array and chop it off when it doesn't match that target element between each 1/2 intervals during the search. It uses a "logarithm" search or "binary chop."
It's fast at O(logn) because we know it has to be sorted first as it finds the index of the target value in a sorted array. Then compares the target value to the middle element of array [A].
time-space complexity¶
- worst complexity: O(logn)
- best complexity: O(logn)
- space complexity: O(1) - constant time
basic implementation¶
You can use Python's BST's bisect(lst, item) module to find left or right index of the item in the list.
You can also use BST's insort(lst, item) module to insert item to left or right index of the list.
bisect_right(lst, item): finds index of item in list, if contains duplicates, returns right most index.
bisect_left(lst, item): returns left most possible index, generates index of existing item.
insort_right(lst, item): inserts item at right most index.
insort_left(lst, item): inserts item at left most index.
pitfalls to avoid¶
There are two pitfalls you want to avoid when implementing BST.
- integer overflow - if left and right of the [A] are large, this causes overflow. You can calculate offset to fix it.
def binary_search(elem, item):
middle = (left + right) // 2 # may cause overflow
def binary_search(elem, item):
middle = left + (right - left) // 2 # can't overflow as offset already calculated here!
-
stack overlow - too many recursive calls, puts local variables onto stack of your PC's memory. You want to consider recursion depth limits, python it's 3000!
-
dex-mod parameter - recursive binary search algorithm doesn't store its original index of the list as you iterate through the 1/2 repeated intervals in the list. This can happen when after first recursion, the index of each new sliced interval remains at 0, as it iterates through the 2nd recursion, it never gets updated!
To fix this, you can adjust for a sub-list indexing by adding a cumulator, and discard on left of the list. A "dex-mode" parameter can be created to track indices during slicing.
common leetcode algorithms¶
queues (FIFO - first in first out)¶
A great example is waiting in queue for a roller coaster ride! The first person in queue gets to ride first(dequeue), and the last person in queue will go last (enqueue)
time-space complexity¶
basic implementation with enqueue vs dequeue¶
Implementation is based on either dequeuing (removing element) or enqueueing (inserting element)
- dequeue: element is removed at the beginning of the queue. Supports O(1) time complexity as it's a constant. Can access, insert, remove element from beginning or end of the list with O(1).
class Node:
def __init__(self, value) -> None:
self.value = value
self.next = None
class Queue:
def __init__(self, value) -> None:
new_node = Node(value)
self.first = new_node
self.last = new_node
self.length = 1
def print_queue(self):
temp = self.first
while temp is not None:
print(temp.value)
temp = temp.next
def enqueue(self, value):
new_node = Node(value)
# if we have an empty queue
# first/last item in line
# need to test if queue is empty
if self.first is None:
self.first = new_node
self.last = new_node
else:
self.last.next = new_node
self.length += 1
def dequeue(self):
if self.length == 0:
return None
temp = self.first
if self.length == 1:
self.first = None
self.last = None
# for two or more items
else:
self.first = self.first.next
temp.next = None
self.length -= 1
# return temp
return temp.value
my_queue = Queue(1)
my_queue.enqueue(2) # 2, 4
print(my_queue.dequeue())
print(my_queue.dequeue())
print(my_queue.dequeue())
# output: return temp
# <__main__.Node object at 0x71ac9c33fe50>
# <__main__.Node object at 0x71ac9c33fdc0>
# None
# output: return temp.value
# 1
# 2
# None
- enqueue: element is inserted at the end of the queue
Essentially, a queue data structure allows us to manage elements that can shrink and grow from one end to the other end. It uses both ends of the queue to "simulate" movement in one direction or FIFO.
A pointer must be maintain to capture the node at the front of the queue or "dequeueing."
common leetcode algorithms¶
stacks (LIFO - last in first out)¶
The perfect example is looking at a stack cookies separated into five separate trays with a gap between them as we don't want to rush those yummy cookies!
- tray 1 (first top level): contains chocolate chip cookies
- tray 2: contains almond cookies
- tray 3: contains peanut butter cookies
- tray 4: contains pistachio cookies
- tray 5 (the lowest level): contains pecan cookides
time-space complexity¶
basic implementation¶
How do I implement a stack algorithm so that I can get to the pistachio cookies from tray 4?
To do this, you are required to first remove tray 1, as it's a FIFO algorithm. And iteratively loop through each lower level until you get to the desired tray 4.
In this data structure, you'll have to first remove top element to access the next element at the top. Last item inserted, is first one to get removed.
To remove top node, change head pointer, until there's a "None" value left to iterate on.
class Node:
def __init__(self, value):
self.value = value
self.next = None
class Stack:
def __init__(self, value):
new_node = Node(value)
self.top = new_node
self.height = 1
def print_stack(self):
temp = self.top
while temp is not None:
print(temp.value)
temp = temp.next
def push(self, value):
new_node = Node(value)
if self.height == 0:
self.top = new_node
else:
new_node.next = self.top
self.top = new_node
self.height += 1
def pop(self):
if self.height == 0:
return None
temp = self.top
self.top = self.top.next
temp.next = None
self.height -= 1
return temp
my_stack = Stack(7)
my_stack.push(11)
my_stack.push(3)
my_stack.push(23)
my_stack.pop()
my_stack.pop()
print("\nStack after push(1):")
my_stack.print_stack()