databricks automation in terraform¶
why databricks?¶
Databricks is a pretty stable and popular data/AI/ML SaaS software that allows you to build, automate, and provision everything from bottom up from serverless to piggybacking their EC2 compute resources against your chose cloud hosting platform. This is what makes this software stable and attractive for many large small and large organizations as it's cloud-agnostic.
The goal here is deconstruct the steps to automate Databricks in Terraform using AWS as our cloud host.
I'll demonstrate how to quickly spin up Databricks ecosystem in Terraform.
So, let's get on to the exciting grunt work here!
databricks mini intro¶
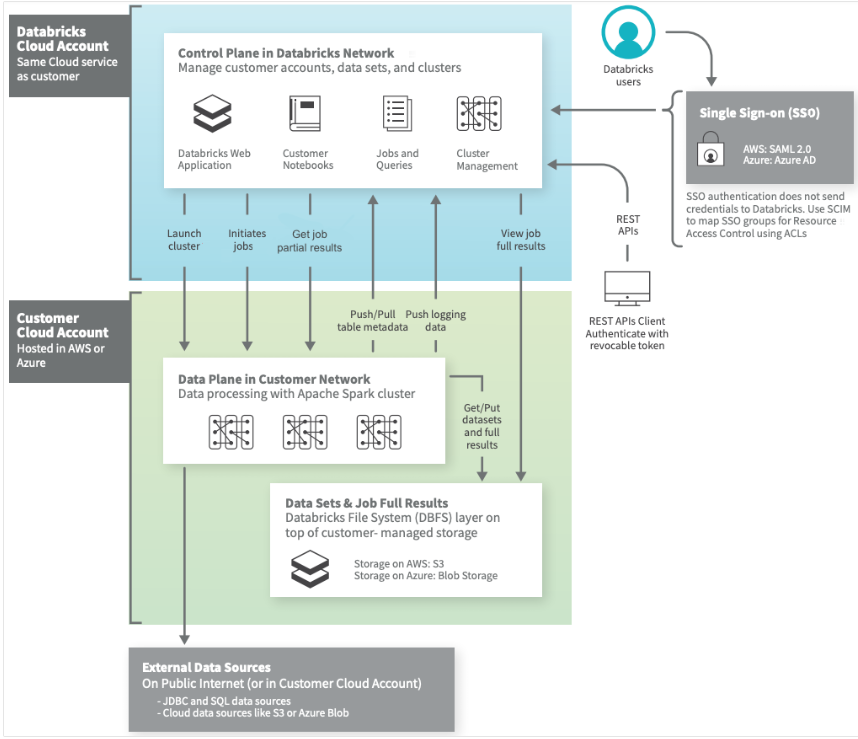
At a high level, what you're seeing here is how databricks cloud account in its own internal compute services (regardless of cloud host) gets provisioned while integrating those services against your cloud hosting services.
So, if you're using AWS, databricks leverages EC2 compute instances to provision their control plane, while it authenticates and configures databricks workspaces and spark clusters configurations with encryption as their application layer will stacked on top of your data plane in your AWS account resources.
databricks SaaS architecture¶
The standard diagram to help shed some visual insights on how databricks architecture is laid out. Databricks oversees their control plane, while the your services will live in the data plane under your cloud-hosted services.
databricks customer vs default setup¶
In an ideal and optimal customer-centric setup, you should only have a single control plane oversees >1 customer managed data planes.
Why?
- It's more cost-effective
- You would only need single sets or resources to instantiate the individual databricks components (workspaces, clusters, notebooks,jobs, unity catalog, metastores, etc...).
- Control plane and data plane ==> 1:many relationship think of it as.
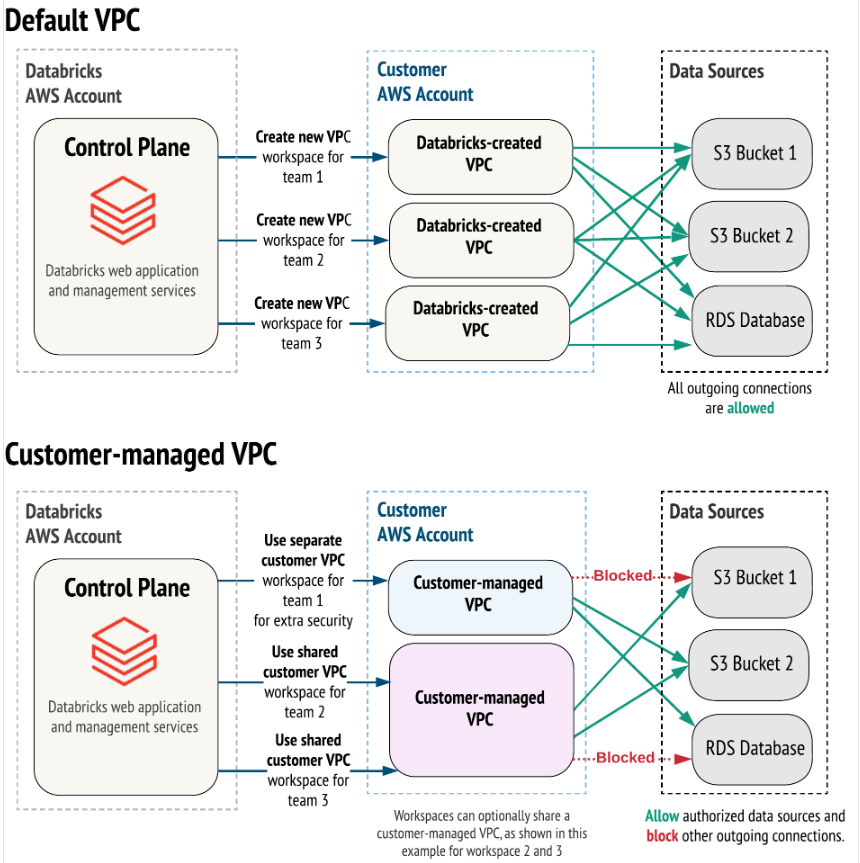
For the purpose of this demo, I'll use the customer-managed VPC architecture to provision the databricks ecosystem.
configurations¶
You'll need to register an AWS and a Databricks free trial accounts first before installing Terraform in your machine.
install terraform¶
You'll need to first install terraform in whichever OS you're using. Since I'm using Linux,
building terraform¶
databricks artifacts¶
A few of the key databricks prerequisites that you'll need, which will allow databricks to interface their control plane with your data plane in your cloud resources (e.g. VPC and its microservices).
The following terraform files are required at minimum:
- providers
- databricks variables
- root bucket
- cross iam account role
These are required if you're provisioning a customer managed VPC and configuring all of your own network and security infrastructure. You'll need these two VPC endpoints at minimum for privatelink to work, while securing your workspaces, clusters, and notebooks and such.
To configure a customer managed networking privatelink VPC endpoints
- Back-end VPC endpoint for SSC relay (cluster secured relay endpoint)
- Back-end VPC endpoint for REST APIs (webapp from workspace URL REST endpoint)
Here are some examples of how to instantiate some of databricks artifacts, and of course it's not the full spectrum of what are required. Just to give some perspectives of how IaC would work for databricks.
# instantiate databricks and aws providers
terraform {
required_providers {
databricks = {
source = "databricks/databricks"
}
aws = {
source = "hashicorp/aws"
version = "~> 4.15.0"
}
}
}
provider "aws" {
region = var.region
}
provider "databricks" {
alias = "mws"
host = "https://accounts.cloud.databricks.com"
username = var.databricks_account_username
password = var.databricks_account_password
}
# instantiate databricks variables
# for variables: "workspace_vpce_service" {} and variable "relay_vpce_service" {},
# these vars have its standard vpce endpoints
variable "databricks_account_id" {}
variable "databricks_account_username" {}
variable "databricks_account_password" {}
variable "root_bucket_name" {}
variable "cross_account_arn" {}
variable "vpc_id" {}
variable "region" {}
variable "security_group_id" {}
variable "subnet_ids" { type = list(string) }
variable "workspace_vpce_service" {}
variable "relay_vpce_service" {}
variable "vpce_subnet_cidr" {}
variable "private_dns_enabled" { default = true }
variable "tags" { default = {} }
locals {
prefix = "private-link-ws"
}
# generate root bucket
resource "databricks_mws_storage_configurations" "this" {
provider = databricks.mws
account_id = var.databricks_account_id
bucket_name = var.root_bucket_name
storage_configuration_name = "${local.prefix}-storage}"
}
# generate cross iam account credential role
resource "databricks_mws_credentials" "this" {
provider = databricks.mws
account_id = var.databricks_account_id
role_arn = var.cross_account_arn
credentials_name = "${local.prefix}-credentials"
}
databricks in terraform modules¶
This is how I would deconstruct the individual databrick artifacts into modules. Then the root module would be provisioning a customer managed VPC with privatelinks, all the necessary credentialing and storage files.
You can see that this code also contains unity catalog.
The S3 bucket is the root bucket.